
基于嵌入的知识图谱实体对齐的基准研究
时间:2022-05-25
Overview
实体对齐寻求在不同的知识图谱(KG)中找到引用同一真实世界对象的实体。KG嵌入的最新进展推动了基于嵌入的实体对齐的出现,它在一个连续的嵌入空间中对实体进行编码,并基于学习到的嵌入来测量实体的相似性。本文对这一新兴领域进行了全面的实验研究。团队调查了最近23种基于嵌入的实体对齐方法,并根据它们的技术和特点对它们进行了分类。此外团队还提出了一种新的KG抽样算法,通过该算法生成了一组具有各种异质性和分布的专用基准数据集,用于现实评估。团队开发了一个开源库,包括12种具有代表性的基于嵌入的实体对齐方法,并对这些方法进行了广泛的评估,以了解它们的优势和局限性。
Background
作为一个新兴的研究课题,基于嵌入的实体对齐的分析和评估仍然存在一些问题。首先,目前还没有对该领域的现状进行总结的工作。基于嵌入的实体对齐的最新发展,以及它的优点和缺点仍有待探索。第二,也没有广泛认可的基准数据集来评估基于嵌入的实体对齐的现实性。不同的评估数据集使得很难对基于嵌入的实体对齐方法进行公平、全面的比较。此外,与现实世界的KG相比,当前的数据集包含更高的等级(即与许多其他实体相连的实体,这相对容易进行实体对齐),因此,许多方法可能在这些有偏差的数据集上表现出良好的性能。此外,这些数据集只关注异质性的一个方面,例如多语言,而忽略了其他方面,例如不同的语法和规模。这给理解基于嵌入的实体对齐的泛化性和健壮性带来了困难。第三,该领域的研究只有一部分带有源代码,这使得很难在这些方法之上进行进一步的研究。由于这些问题,迫切需要对基于嵌入的实体对齐方法进行全面和现实的重新评估,并进行深入分析。
Contributions
- 全面的调查。调查了最近23种基于嵌入的实体对齐方法,并从不同方面对它们的核心技术和特点进行了分类。我们还回顾了每个技术模块的流行选择,简要概述了该领域。
- 基准数据集。为了进行公平和现实的比较,团队通过抽样现实世界中的KGs DBpe dia、Wikidata和YAGO构建了一组五倍分割的专用基准数据集,考虑到实体度、多语言、模式和规模等方面的异质性。团队提出了一种新的采样算法,可以使样本的属性(如度分布)更接近其来源。
- 开源库。团队使用Python和TensorFlow开发了一个开源库OpenEA。该库集成了12种具有代表性的基于嵌入的实体对齐方法,属于多种技术。iTunes采用了灵活的体系结构,可以轻松集成大量现有的KG嵌入模型(已经实现了8个代表性模型)以实现实体对齐。
- 综合比较和分析。团队在数据集上对12种具有代表性的基于嵌入的实体对齐方法的有效性和效率进行了全面的比较。通过使用开源库从头开始训练和调整每种方法,以确保公平评估。
- 探索性实验。团队在文献中已有的基础上进行了三个实验。团队首先分析了实体嵌入的几何特性,以了解它们与最终性能之间的潜在联系。注意到许多KG嵌入模型还没有被用于实体对齐,团队探索了其中8个流行的模型。此外团队还将基于嵌入的方法与几种常规方法进行了比较,以探索它们的互补性。
- 未来的研究方向。基于调查和实验结果,团队对未来工作的几个重要研究方向进行了全面的展望,包括无监督实体对齐、长尾实体对齐、大规模实体对齐和非欧几里德嵌入空间中的实体对齐。
Literature Review
Knowledge Graph Embedding
现有的KG嵌入模型大致可分为三类:(i)平移模型,例如TransE、TransH、TransR和TransD;(ii)语义匹配模型,例如DistMult、ComplEx、HolE、SimplE、RotatE和TuckER;以及(iii)深层模型,例如ProjE、Conv、R-GCN、KB-GAN和DSKG。这些模型通常用于联系预测。网络嵌入是其中一个相关的领域,它学习顶点表示以捕捉它们的相似性。然而,网络中的边缘携带简单的语义。FB15K和WN18是KGs中联系预测的两个基准数据集。评估中广泛使用了三个指标:(i)顶级关系结果中正确的比例(称为Hits@m,例如,m=1),(ii)正确联系的平均排名(MR),以及(iii)平均倒数排名(MRR)。
Conventional Entity Alignment
传统方法主要从两个角度解决实体对齐问题。一个是基于OWL语义规定的一个等价推理。另一种是基于相似性计算,它比较实体的符号特征。最近的研究还使用统计机器学习和众包来提高准确性。此外,在数据库领域,检测重复实体(也称为记录链接或实体解析)已被广泛研究。这些方法主要依赖实体的文字信息。自2004年以来,OAEI2已成为本体对齐工作的主要场所。它还组织了最近几年实体对齐的评估跟踪。首选的评估指标是准确度、召回率和F1分数。
Embedding-based Entity Alignment
许多现有的方法使用平移模型(例如,TransE)来学习基于关系三元组的对齐实体嵌入。最近的一些方法采用了图卷积网络(GCN)。除此之外,一些方法还结合了属性和值嵌入。此外,还有一些用于(异构信息)网络对齐或跨语言知识投影的方法,这些方法也可以针对实体对齐进行修改。还值得注意的是,两项研究设计了基于嵌入的数据库实体解析方法。它们基于单词嵌入表示实体的属性值,并使用嵌入距离比较实体。然而,他们假设所有实体遵循相同的模式,或者属性对齐必须是1对1映射。由于不同的KG通常使用不同的模式创建,因此很难满足这些要求。就目前而言,没有广泛认可的基准数据集来评估基于嵌入的实体对齐方法。常用的数据集是DBP15K和WK3L。
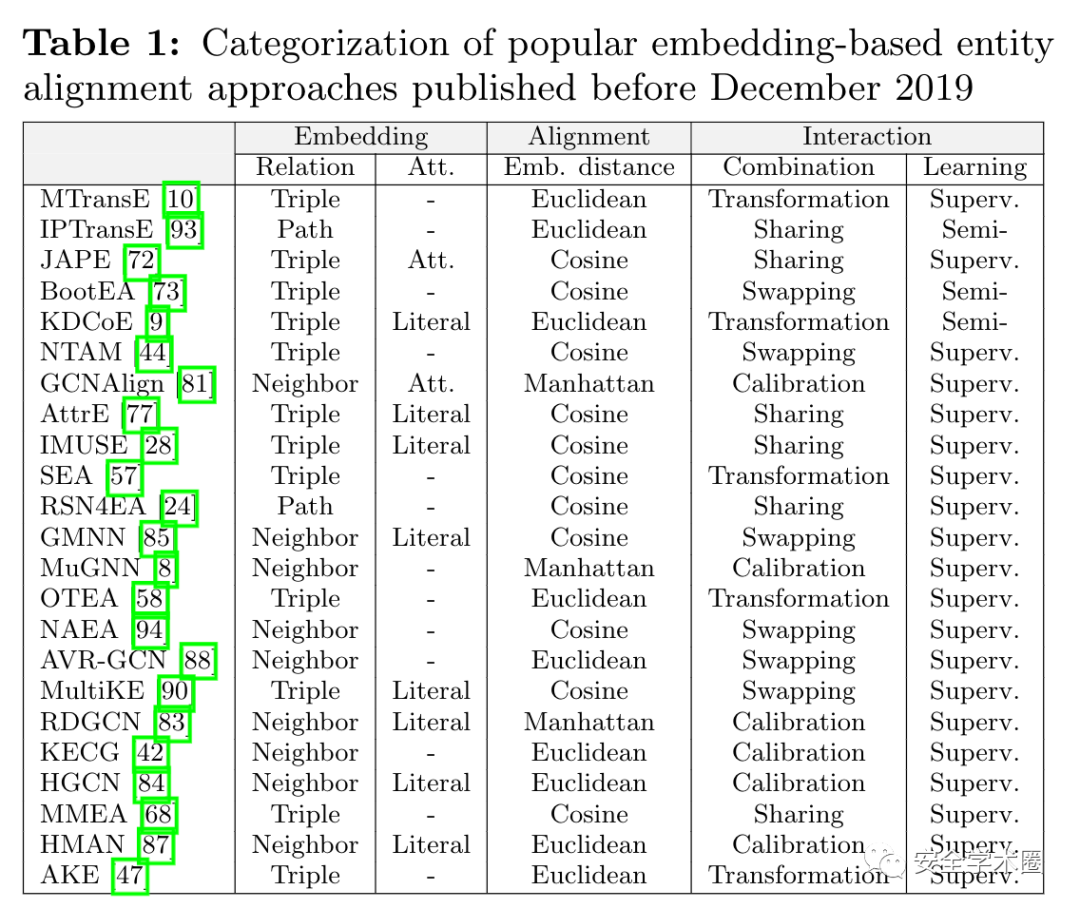
Categorization of Techniques
Embedding Module
嵌入模块将KG编码到低维嵌入空间中。根据使用的三元组类型,可将KG嵌入模型分为两种类型,即关系嵌入和属性嵌入。前者利用关系学习技术来捕获结构,后者利用实体的属性三元组。所有现有的方法都采用关系嵌入法。下面是三种有代表性的实现方法:
基于三元组的嵌入捕获了关系三元组的局部语义。许多KG嵌入模型都属于这一类,它定义了一个能量函数来衡量三元组的可扩展性。例如,TransE将关联解释为从头部实体嵌入到尾部的转化。三元关系 的能量为:
其中 表示向量的 - 或 -范数。TransE优化了边际排名损失,以预先定义的边际将正三元组和负三云组分开。负三元组可以使用均匀或负采样或连续采样生成。
基于路径的嵌入利用了跨越关系路径的关系的长期依赖性。关系路径是一组三元组,例如 , 。IPTransE通过推断直接关系和多跳路径之间的等价性,对关系路径进行建模。假设从 到 有直接关系 。IPTransE期望 的嵌入类似于路径嵌入,路径嵌入被编码为其组成关系嵌入的组合:
其中 是一种序列合成操作,如最小化。然而,IPTransE忽略了实体。另一项工作是RSN4EA,它修改了递归神经网络(RNN),以便对实体和关系的序列进行建模。
基于邻域的嵌入使用由实体之间的大量关系构成的子图结构。GCN非常适合对这种结构进行建模,目前已经用于基于嵌入的实体对齐。GCN由多个图卷积层组成。设 为KG的邻接矩阵, 为特征矩阵,其中每一行对应一个实体。从 层到 层的典型传播规则是:
其中 且 为单位矩阵. 是 的对角矩阵。 是可学习的权重矩阵. 是类似 的激活函数。
有几种方法使用属性嵌入来增强实体的相似性度量。属性嵌入有两种方法:
属性相关性嵌入考虑属性之间的相关性。如果属性经常一起用来描述一个实体,那么它们就被认为是相关的。JAPE基于相似实体应具有相似相关属性的假设,利用这种相关性进行实体对齐。对于两个属性,它们相关的概率为
其中可以通过最大化所有属性对的概率来学习属性嵌入。
文字嵌入将文字值引入到属性嵌入中。AttrE提出了一种字符级编码器,能够在训练阶段处理看不见的值。 是带字符的文字,其中 是第 字符。AttrE 这样嵌入 :
这种表示将文字视为实体,而像TransE这样的关系嵌入模型可以用于从属性三元组中学习。然而,基于字符的文字嵌入在跨语言环境中可能会失效。
Alignment Module
对齐模块使用种子对齐作为标记的训练数据来捕获实体嵌入的对应关系。两个关键点是选择距离度量和设计对齐推理策略。
- 距离度量。余弦、欧几里得和曼哈顿是三种广泛使用的度量标准。
- 对齐推理策略。目前使用的方法均是贪婪搜索。
Dataset Generation
团队选择了三个著名的KG作为来源:DBpedia(2016-10)、Wikidata(20160801)和YAGO 3。此外,团队还考虑了DBpedia的两个跨语言版本:英语-法语和英语-德语。团队使用IDS算法生成具有15K和100K实体的两种大小的数据集。
团队评估IDS(degree-based sampling)和数据集的质量。团队在现有图形采样算法的基础上设计了两种基线方法:
随机对齐采样(RAS) 首先在两个KG之间随机选择一个固定大小(例如15K)的实体对齐,然后提取其头部和尾部实体都在采样实体中的关系三元组
基于PageRank的采样(PRS) 首先根据PageRank分数从一个KG中采样实体(不参与任何对齐的实体将被丢弃),然后从其他KG中提取这些实体的对应项。
Open-Source Library
团队使用Python和TensorFlow开发了一个开放的源代码库,名为OpenEA,用于基于嵌入的实体对齐。软件架构如图所示。
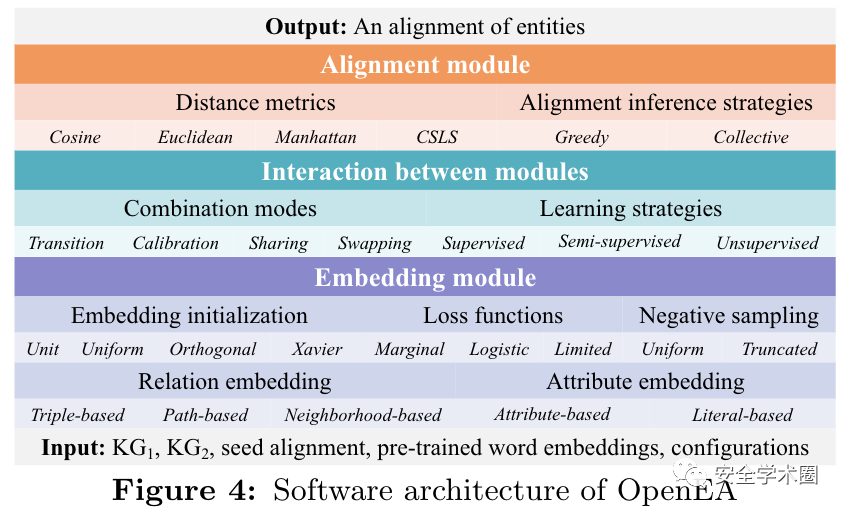
设计目标和特点包括三个方面:
松耦合。嵌入和对齐模块的实现是相互独立的。OpeneEA提供了一个带有预定义输入和输出数据结构的框架模板,使这些模块成为一个集成且完整的管道。用户可以在这些模块中自由调用和组合不同的技术,以开发新的方法。
功能性和可扩展性。OpenEA实现了一组必要的函数作为其底层组件,包括嵌入模块中的初始化函数、丢失函数和负采样方法;互动模式下的组合与学习策略;以及对齐模块中的距离度量和对齐推理策略。除此之外,OpenEA还提供了一组灵活的高级功能,以及调用这些组件的配置选项。通过这种方式,可以通过添加新的配置选项轻松集成新功能。
现成的方法。为了方便使用OpenEA,团队整合或重建12种具有代表性的基于嵌入的实体对齐方法,这些方法属于多种技术,包括MTransE、IPTransE、JAPE、KDCoE、BootEA、GCNAlign、AttrE、IMUSE、SEA、RSN4EA、MultiKE和RDGCN。
 15527777548/18696195380
在线咨询
15527777548/18696195380
在线咨询