
浅析数据安全脱敏工具
时间:2018-01-27
既要挖掘数据价值,又要保护数据隐私。传统上我们的方法是在网络、服务器等基础架构方面做了大量工作,但新的挑战是随着大数据的使用,创造了海量的数据,这些数据存在应用、大数据平台甚至云端。因此在这个形势下,安全防护的重心转移到了数据本身。
但这也有很大挑战,很难保证所有的数据都得到了必要的安全控制。当然你也可以说,我对数据统统加密,但实际上这不现实,首先加密后的数据是无法分析的。其次在数据海量移动的情况下,不可能安全的分发密钥、解密。所以,不管数据在哪里,都要对数据进行保护,就成了时下比较热门的课题方向。
如果要进行数据安全保护,有几个地方是大家特别关心的集中领域:
1、大数据平台
大型互联网公司有数不清的数据来源,一个公司数下来几十上百个app都习以为常,这些来源里有很多敏感数据。再加上数据进入平台后的分析,再加工,输出,整个数据遍布各个环节。因此这是数据安全保护的一个重点。
2、云计算
如果公司有有云计算国际业务的话,那就更头疼了。通常云计算数据中心为了可靠性和性能原因,会在不同国家部署节点,每个国家要求又不一样,欧盟和美国的法律还有相互冲突的地方,再加上数据向境外转移的要求,就把合规这事搞得特别复杂。
3、个人敏感信息
姓名、地址、手机号码、身份证号这些都是个人的敏感数据。也是数据安全保护的重点,如何能分析加工这些数据,又不暴露个人隐私信息?
4、金融数据
典型欺诈分子用到的信息,身份证号、银行卡号、手机号、CVV等信息。也是重点保护对象。网络欺诈之所以猖獗,其中一个重要原因就是这部分数据泄漏。
一、数据脱敏工具
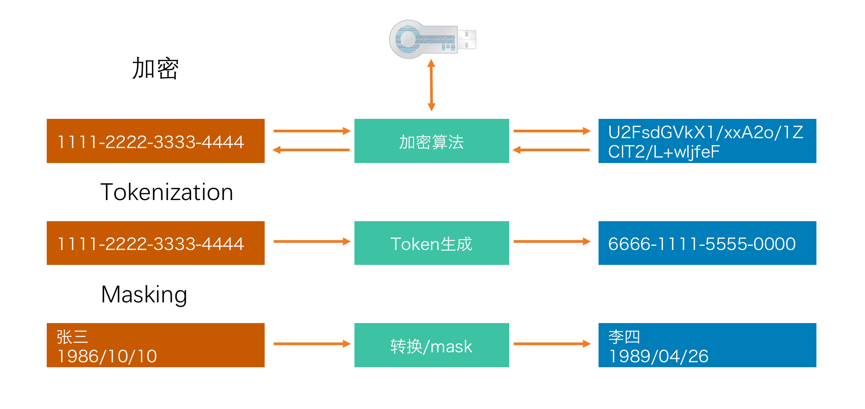
要对狭义的数据安全进行保护,有几个基本的工具可选,分别是令牌化(tokenization)、屏蔽(masking)和加密(encryption)。也还有一些其他手段,但成熟性不够,短期内还不能大规模工程化。
1、Tokenization
有点像抓娃娃机用的代金币,本身不是钱,但可以玩游戏。Tokenization的意思是,把真实的数据用一个令牌来代替,而真实的数据则单独存储,你访问的只是一个没有具体意义的令牌,最常见用于金融行业的银行卡号保护。令牌只是一个随机数,比如银行卡号在这里就是一个随机的16位数字,这个随机数字和真实卡号没有数学关系,只是一个映射。这种方式可以大量减少真实卡号在系统中的流转,提供了较好的安全性,大家只要通过令牌这个客户标识符来进行工作即可。
但是Tokenization这个技术,无法适用于复杂的数据类型,只能用于比较简单固定的对应关系场景,也不适用于动态场景。
2、masking
屏蔽这个方法其实存在很多年了,既保留数据含义,又能保护部分隐私。比如可以用一个随机数来替换身份证号码,也可以更复杂一些,保留身份证的地域、姓名,将其他信息替换掉,不影响分析中使用。这个技术最适合于在分析和测试环节使用,在安全资源不足的情况下,也是最经济的一种手段。屏蔽有两种部署方式,持久性屏蔽和动态屏蔽,在国内的翻译分别是静态脱敏和动态脱敏。静态脱敏主要用于非生产目的,典型的测试和分析场景,或者培训等环节。动态脱敏实时的修改传送的数据—并不改变存储数据,这是和持久化屏蔽的主要区别。因此,要考虑在不同场景下的用法。
3、加密
加密也是主要工具之一,而且现在加密也和Hadoop平台、云架构广泛集成,加密可以用在很多场景下。但加密不能用在分析、测试环节。而且加密后的数据在很多国家是不允许出境的。需要注意的是加密不是指简单的密码加密,而是基于KMS的密钥机制。
另外值得一提的是同态加密技术,现在很火热。同态加密可以理解为既能够屏蔽,也能加密,同时还能用于数据计算。但还只是个概念,同态系统需要庞大的计算资源,很不经济的对加密的数据进行基本数学分析。期待数学科学家们能在我们有生之年,成为一个现实的技术选择,目前来看还不实际。
4、抑制
这种方法使用一个通用值替换敏感数据,比如电话号码为139********,这种方式最简单、最快,但在数据分析上价值就很低了。在性能很重要的时候可以考虑这个方法,对数据进行实时替换。
5、数据发现
保护数据,首先就要能够发现数据,并且确定敏感数据的类型才能谈到保护。数据发现通常两个方法,元数据和正则表达式。元数据发现不是检查每个数据,而是查数据表列长度、列名、结构等信息,比如对信用卡号这种固定长度的扫描,或者对4个汉字字符,且首汉字是姓的姓名扫描。正则表达式则检查数据本身。精确率再高一些,就要用到启发式扫描或者位置检查,机器学习在这个领域也开始有应用了。
二、部署模式
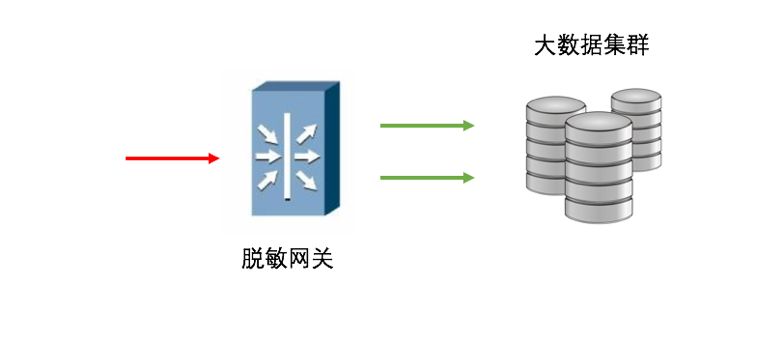
1、网关型
数据包实时传递,敏感数据在网关处进行处理,位置一般放在靠近数据存储的地方,在插入集群之前进行处理,由于大数据平台的海量数据入库,所以能够告诉并行处理是关键,网关必须在保证大数据平台服务的同时进行数据替换工作。大数据平台可能同时有几千台服务器在并行工作,网关必须非常快,所以网关这一层一般不提供深入分析。比如为了解决性能问题,需要明确告知网关敏感字段的位置以便替换。
如果在云模式下,则是在数据转移到云之前进行处理(一般是加密)。网关对于性能要求比较高,而且能够解析流量数据,并对其进行脱敏处理。
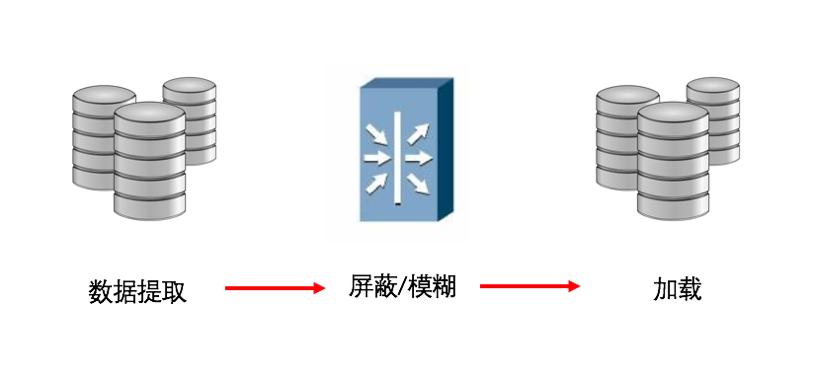
2、HUB
HUB的原理都还记得?一个多端口转发器,这个部署方式也类似。从n个数据源提取数据,将其移动到n个目的地。“HUB”在这里负责管理、应用各种数据转换策略,其实他也是ETL的一种,ETL用于数据的提取、转换、加载,但是比ETL又要先进一些,它可以发现数据,创建新的数据集,使用不同的脱敏方式,再应用到不同的用户。甚至同一个数据,可以根据策略,设置不同人看到的内容不一样。下图是一个最基本的部署形式。
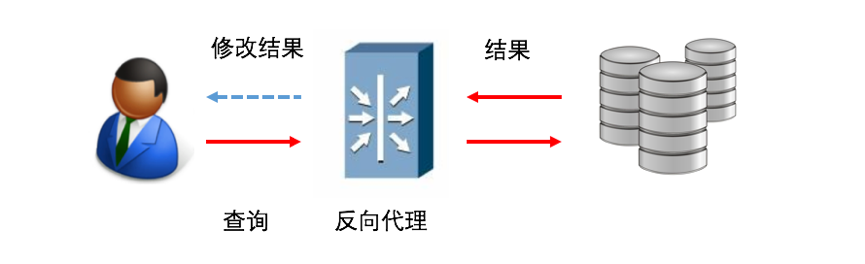
3、动态脱敏&反向代理
和网关类似串联在数据流中,主要用于用户和数据库之间。代理可以改变用户的query,然后通过修改查询结果返回,对用户来说是透明的。反向代理可以是在数据库上的应用程序,也可以是串联设备。它的主要优势是保护数据的同时,而不需要更改数据库。适合于比较固定的字段,身份证、手机号等,也可以用这个方法来实现Tokenization。主要用途是动态保护数据,也可以基于用户的身份、查询语句做修改替换。
三、使用建议
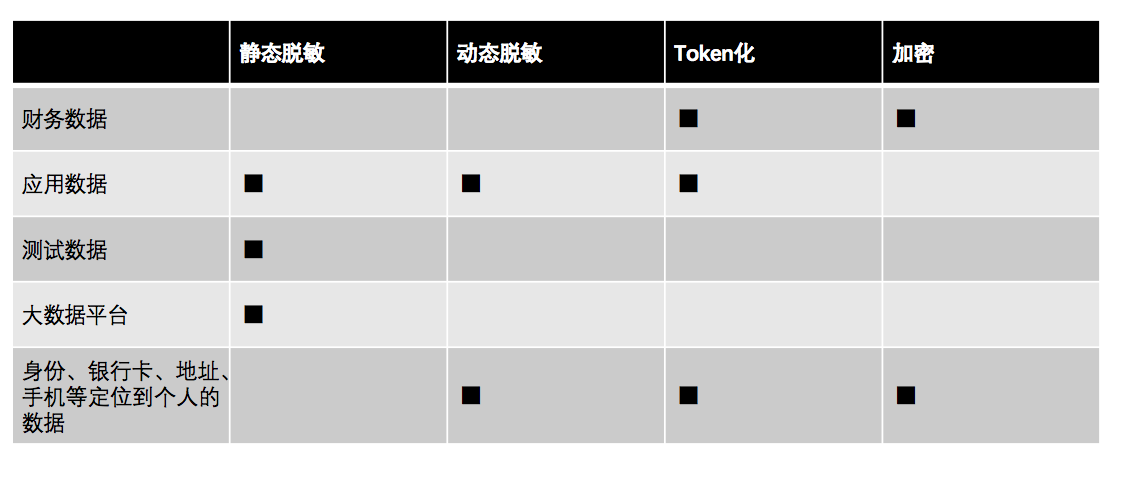
以上手段并不是单一的,可在不同的数据情形下提供不同的手段进行保护:
上一篇:顶尖Hacking技术盛宴(文末福利) 下一篇:Imperva的免费数据分类器
 15527777548/18696195380
在线咨询
15527777548/18696195380
在线咨询